


Skiing with Snowflake
Supercharge your compute strategy with Apache Iceberg, Snowflake, Apache Spark, AWS Glue, and Project Nessie.


In this article, I will demonstrate how to formulate a lakehouse strategy that pairs well with Snowflake.
A few months ago, I began exploring opportunities to develop ETL pipelines in Ray. I had to perform my PoC on SnowflakeDB. Unfortunately, Ray Community Edition lacks APIs for reading data from Snowflake. So, I created my own Dataset API. This article details how to read data from SnowflakeDB in Ray.
To perform any compute in Ray, we need to do a SELECT * from the respective table to read that data into Ray. Snowflake charges us the standard WH rate for this query.
If you perform multiple experiments on Ray with Snowflake, be prepared to spend some big bucks. Additionally, there is latency associated with this ingest as the Ray application must wait for the SELECT * to complete before it can start operating on this data. This latency increases with the volume of data being operated on.
What happens during aSELECT *?
I have certain assumptions regarding what happens when you do SELECT * on Snowflake from a Python application. Here are a few:
Snowflake stores data in a proprietary storage format. Vino Duraisamy’s article talks more about the workings of this proprietary format.
Upon reading, Snowflake converts data from its proprietary format to compressed Parquet file(s) and provides URLs of corresponding S3 endpoints.
The Python connector then starts hitting these S3 endpoints to load the data into memory as Apache Arrow tables.
The assumptions regarding step 2 are based on my understanding of their Python-connector code and the latency observations.
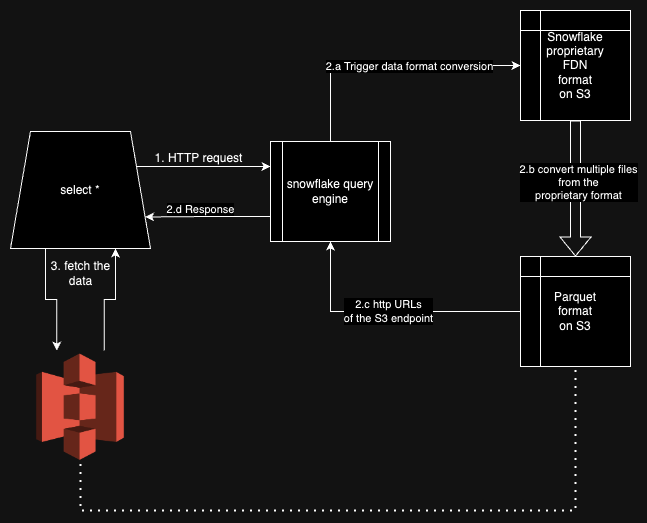
Now, if our table contains a few hundred gigabytes of data, we'll be blocked waiting for steps 1 & 2 to complete. While we can use larger warehouses to expedite step 2, step 3 can be executed in parallel. The fetch_arrow_batches API pings S3 URLs one-by-one. Although we can get apparent parallelism by multi-threading this invocation.
Workaround
Given the limitations of using SELECT *, engineers can infer the necessity of adopting an open data storage format. Open data storage formats, designed to be readable by various compute engines, alleviate limitations such as those presented by Snowflake's data format conversion.
Snowflake is doubling down on interoperability with Apache Iceberg. They have a bunch of content on this interoperability. I’ll refer to the latest one that I could get my hands on.
This eliminates the need for a data warehouse and marginally reduces experimentation expenses. Users can now assume that Iceberg data is available and proceed with experiments, ushering us into the Lakehouse world.
Welcome to the Lakehouse world!
The Lakehouse Strategy
Apache Iceberg has great documentation and ample resources and I would leave it to the reader to familiarise themselves with the exact workings of this technology.
This definitive diagram speaks volumes about the possibilities of the Apache Iceberg format.
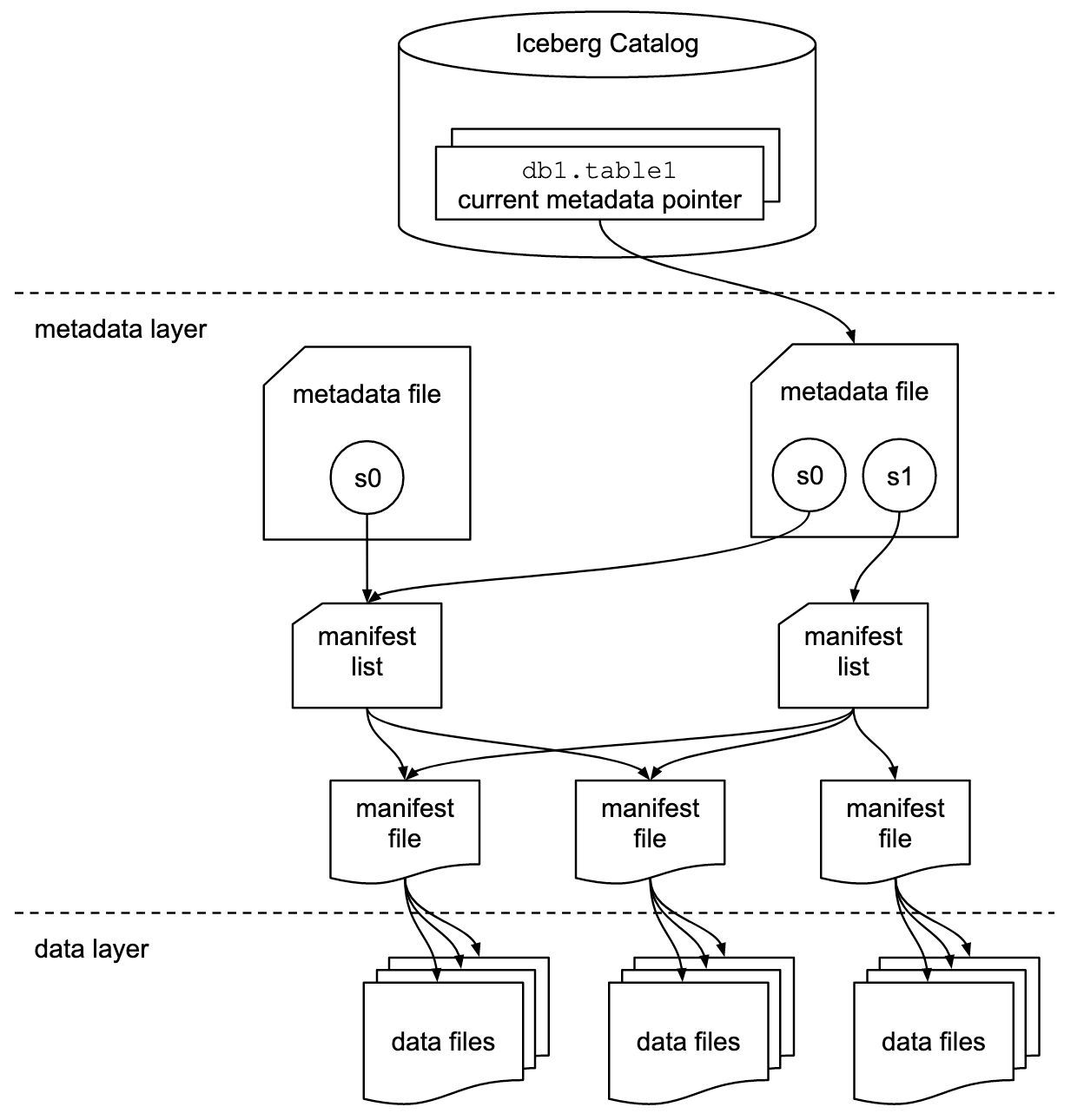
Since we are discussing using Apache Iceberg with the Snowflake Cloud Data Warehouse, selecting a cloud storage solution is the first and easiest step of our Lakehouse Strategy. Iceberg’s ACID transactions are centered around the operations of the Iceberg Catalog and this system will quite literally make or break our strategy.
Assuming we are using AWS S3 for storage, let’s understand how storage works at different layers of the architecture.
The data layer lives in S3 ✅.
The metadata layer lives in S3 as well ✅.
Where does the catalog live 🤔?
The Iceberg community offers various resources and options for selecting the catalog. We will explore the following catalogs, understand how to set them up, and evaluate associated tradeoffs:
Snowflake Iceberg Catalog
AWS Glue Data Catalog
Project Nessie
Snowflake Iceberg Catalog
Let’s understand the capabilities of the Snowflake + Apache Iceberg integration.
Bring your storage: Snowflake writes to the chosen storage.
Snowflake will manage its own Iceberg catalog.
Spark can read data using the Snowflake catalog.
However, Spark can't write using this catalog.
Snowflake doesn’t charge you for that storage. Additionally, DDL & DML ops from the snowflake connectors don’t discriminate in any manner.
Setup
I have created a Terraform that can be applied to deploy Iceberg tables on Snowflake in this GitHub gist. Here are the steps:
Create a S3 bucket and an IAM role with RW access to this S3 bucket.
Configure an
external volumein Snowflake. This external volume is configured with the AWS IAM role & the S3 bucket from step 1.Snowflake returns an IAM user & session ID. Edit the trust policy of the role in step 1 to permit this IAM user & session.
Now that we have allowed Snowflake to write to the designated S3 location; writes can be channeled through the external volume. Creating iceberg table dumps the data into the above S3 bucket in our desired location in the Iceberg table format.
How to use Iceberg tables?
Create the iceberg table in Snowflake.
CREATE ICEBERG TABLE -- magic words for creating the external iceberg table
my_sf_db.public.my_iceberg_table (
boolean_col boolean,
int_col int,
string_col string,
time_col timestamp_ltz
)
CATALOG = 'SNOWFLAKE' -- this is the snowflake managed catalog
EXTERNAL_VOLUME = 'MY_ICEBERG' -- same volume that we deployed earlier
BASE_LOCATION = 'my_db';
insert into my_iceberg_table values (true, 1, 'abc', sysdate()); -- insert a row
-- do a few more inserts to increase data volume exponentially ;-)
insert into my_iceberg_table select * from my_iceberg_table;
insert into my_iceberg_table select * from my_iceberg_table;
insert into my_iceberg_table select * from my_iceberg_table;
insert into my_iceberg_table select * from my_iceberg_table;
View the data in S3.
# you can locate your files of data layer
# in this folder hierarchy
aws s3 ls s3://my-iceberg
Read it in Pyspark.
import os
import re
from boto3 import Session
from pyspark.sql import SparkSession
session = Session()
credentials = session.get_credentials()
current_credentials = credentials.get_frozen_credentials()
os.environ["AWS_ACCESS_KEY_ID"] = current_credentials.access_key
os.environ["AWS_SECRET_ACCESS_KEY"] = current_credentials.secret_key
os.environ["AWS_SESSION_TOKEN"] = current_credentials.token
# Initialize Spark session with required packages
spark = (
SparkSession.builder.appName("Iceberg and Snowflake Example")
.config(
"spark.jars.packages",
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1,"
"net.snowflake:snowflake-jdbc:3.14.2,"
"software.amazon.awssdk:bundle:2.20.160,"
"software.amazon.awssdk:url-connection-client:2.20.160,"
"net.snowflake:spark-snowflake_2.12:2.12.0-spark_3.4",
)
.config(
"spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
)
.config("spark.sql.iceberg.vectorization.enabled", "false")
.getOrCreate()
)
# Set Snowflake catalog
spark.conf.set(
"spark.sql.defaultCatalog",
"snowflake_catalog"
)
spark.conf.set(
"spark.sql.catalog.snowflake_catalog",
"org.apache.iceberg.spark.SparkCatalog"
)
spark.conf.set(
"spark.sql.catalog.snowflake_catalog.catalog-impl",
"org.apache.iceberg.snowflake.SnowflakeCatalog",
)
spark.conf.set(
"spark.sql.catalog.snowflake_catalog.uri",
f"jdbc:snowflake://{os.environ['SNOWFLAKE_ACCOUNT']}"
".snowflakecomputing.com",
)
# Set Snowflake connection properties
spark.conf.set(
"spark.sql.catalog.snowflake_catalog.jdbc.user",
os.environ["SNOWFLAKE_USER"]
)
spark.conf.set(
"spark.sql.catalog.snowflake_catalog.jdbc.role",
os.environ["SNOWFLAKE_ROLE"]
)
spark.conf.set(
"spark.sql.catalog.snowflake_catalog.jdbc.private_key_file",
os.environ["SNOWFLAKE_PRIVATE_KEY_FILE"],
)
spark.conf.set(
"spark.sql.catalog.snowflake_catalog.io-impl",
"org.apache.iceberg.aws.s3.S3FileIO"
)
# configure s3 for the hadoop catalog. this is required cuz snowflake
# seems to be configuring the hadoop catalog as well! you'll see the
# infamous version-hint.txt file.
spark.conf.set(
"spark.hadoop.fs.s3a.impl",
"org.apache.hadoop.fs.s3a.S3AFileSystem"
)
spark.conf.set(
"spark.hadoop.fs.s3a.aws.credentials.provider",
"org.apache.hadoop.fs.s3a.TemporaryAWSCredentialsProvider",
)
spark.conf.set(
"spark.hadoop.fs.s3a.endpoint", "s3.amazonaws.com"
)
spark.conf.set(
"spark.hadoop.fs.s3a.access.key", current_credentials.access_key
)
spark.conf.set(
"spark.hadoop.fs.s3a.secret.key", current_credentials.secret_key
)
spark.conf.set(
"spark.hadoop.fs.s3a.session.token", current_credentials.token
)
spark.conf.set(
"spark.hadoop.fs.s3a.endpoint.region", os.environ["AWS_REGION"]
)
spark.sql("use my_sf_db.public").show()
spark.sql("SHOW TABLES").show()
tab = spark.table("my_sf_db.public.my_iceberg_table")
tab.show()
print(tab.count())
print(tab.schema)
# this will throw an error cuz snowflake catalog doesn't
# implement writes!
tab.writeTo(
"my_sf_db.public.my_iceberg_table"
).using("iceberg").append()
spark.stop()
If you have done some legendary ETL and want to write it back, you can’t it using the default Snowflake catalog. Refer to these two pieces of code in apache-iceberg:1.5.0 for yourself:
Base Metastore Ops — this is the base table of Snowflake Metastore ops.
Although you can use the Spark <> Snowflake connector for writes, they may be inconvenient to implement and will pass through the Snowflake DWH, diluting the proposition of reducing dependency on Snowflake warehouse in the ETL phase.
AWS Glue Data Catalog
Let’s understand the capabilities of the AWS Glue Data Catalog + Apache Iceberg integration.
Spark’s
CREATE DATABASEAPI can create the catalog in AWS Glue.Glue catalog’s table params point to the latest metadata location. This location is expressed as a S3 URI.
Snowflake can only read from this catalog. It can’t write to it 🤷♂.
Snowflake is very generous in its read operations. It can connect with the Glue data catalog directly.
Snowflake tables need to be refreshed to reflect any metadata changes.
If the snowflake iceberg table is directly connected to Glue, it’ll pull the metadata info internally & update itself.
If you don’t want to connect it with Glue, you can manually obtain the metadata location from Glue & pass it as a parameter to the Snowflake refresh.
Setup
Configure the S3 bucket & external volume for the Snowflake read access as in the previous demo.
AWS Glue Data Catalog itself doesn't entail any setup overhead, making it reliable & easy to use. Writes will be done entirely by Pyspark. Reads can be done by anyone. Duh!
How to use the Iceberg tables?
Write Iceberg tables using Pyspark.
import os
import boto3
from pyspark.sql import SparkSession
warehouse_path = "s3://my-iceberg/"
def create_spark_iceberg(catalog_nm: str) -> SparkSession:
# You can set this as a variable if required
spark = (
SparkSession.builder.config(
"spark.jars.packages",
",".join(
[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1",
"software.amazon.awssdk:bundle:2.20.160",
]
),
)
.config(
"spark.sql.extensions",
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
)
.config(
f"spark.sql.catalog.{catalog_nm}", "org.apache.iceberg.spark.SparkCatalog"
)
.config(f"spark.sql.catalog.{catalog_nm}.warehouse", warehouse_path)
.config(
f"spark.sql.catalog.{catalog_nm}.catalog-impl",
"org.apache.iceberg.aws.glue.GlueCatalog",
)
.config(
f"spark.sql.catalog.{catalog_nm}.io-impl",
"org.apache.iceberg.aws.s3.S3FileIO",
)
.getOrCreate()
)
return spark
_catalog_nm = "iceberg_catalog"
spark = create_spark_iceberg(_catalog_nm)
table = f"{_catalog_nm}.{os.environ['DATABASE_NAME']}.{os.environ['TABLE_NAME']}"
table_path = f"{warehouse_path}{os.environ['DATABASE_NAME']}/{os.environ['TABLE_NAME']}"
glue_client = boto3.client("glue")
# can also be done by spark sql as follows.
# spark.sql(f'create database {os.environ["DATABASE_NAME"]}')
try:
glue_client.create_database(
DatabaseInput={
"Name": os.environ["DATABASE_NAME"],
"Description": f'{os.environ["DATABASE_NAME"]} Iceberg Database',
}
)
except Exception:
# cheap manner of handling already existing catalog!
pass
# based on your deployment strategy, you can choose to
# provision catalogs separately say, as part of your IaC
df = spark.createDataFrame(
[
("2021-01-01", 1, "A", "X", "2021-01-01"),
("2021-01-01", 2, "B", "Y", "2021-01-01"),
("2021-01-01", 3, "C", "Z", "2021-01-01"),
],
["col_1", "col_2", "col_3", "col_4", "col_5"],
)
df.writeTo(table).using("iceberg").tableProperty(
"location", table_path
).tableProperty(
"write.format.default", "parquet"
).partitionedBy(df.col_5).append()
tab = glue_client.get_table(
DatabaseName=os.environ["DATABASE_NAME"], Name=os.environ["TABLE_NAME"]
)
# you can configure your iceberg table using this metadata location!
# remember to strip the leading bucket name from the string.
print("new_metadata", tab["Table"]["Parameters"]["metadata_location"])
spark.read.table(table).show()
See the data in S3!
# you can locate your files of data layer
# in this folder hierarchy
aws s3 ls s3://my-iceberg
# get the latest metadata location from glue data catalog
aws glue get-table --database-name <DATABASE_NAME> --name <TABLE_NAME> | jq -r ".Table.Parameters.metadata_location"
Read it in Snowflake. Mind it, we’ll be getting the metadata location from Glue.
-- this means that metadata is on the external volume itself
CREATE OR REPLACE CATALOG INTEGRATION icebergCatalogExt
CATALOG_SOURCE=OBJECT_STORE
TABLE_FORMAT=ICEBERG
ENABLED=TRUE;
-- use volume as configured. obtain metadata file path from the spark job.
CREATE ICEBERG TABLE read_iceberg_table_nessie
EXTERNAL_VOLUME='MY_ICEBERG'
CATALOG = 'icebergCatalogExt'
METADATA_FILE_PATH='<new_metadata>'
Although Snowflake directly connects with Glue thereby doing away with the necessity of manually specifying the metadata_file_path param, I prefer the above method of not creating a Glue-specific integration. This reduces**vendor tie-in** and makes the catalog integration on the Read end, i.e. Snowflake, thoroughly general purpose.
Project Nessie
Let’s understand the capabilities of the Project Nessie + Apache Iceberg integration.
One tradeoff with using AWS Glue Data Catalog is the vendor lock-in that comes with the catalog. If you are in a non-AWS environment, then the AWS glue data catalog becomes a no-go.
In this case, Project Nessie is a good alternative because it can be entirely self-hosted. Incorporating Project Nessie makes our system trulyvendor agnostic and makes it stand tall on the giant shoulders of the OSS community 💪.
Setup Project Nessie. Spark’s
CREATE DATABASEAPI can create the catalog in Nessie using its SQL extensions.Just like Glue, the metadata location can be easily obtained from Nessie and this location is expressed as a S3 URI.
Snowflake can only read from this catalog. It can’t write to it. Similar to the previous AWS Glue catalog demo.
Setup
Configure the S3 bucket & external volume for the Snowflake read access as in the previous demos.
Configure project Nessie deployment.
docker run -p 19120:19120 projectnessie/nessie:latestAccess the catalog info on you
http://0.0.0.0:19120.
Project Nessie deployment seems a bit challenging as it is a fairly new technology. Convincing your team to take this up will require some massive effort! The remainder of the setup is quite similar to that of the AWS Glue Data Catalog.
How to use the Iceberg tables?
Create Iceberg tables using Pyspark. This implementation only differs from the previous demo in the choice of catalog. Everything else remains configurable.
import os
from pyspark.sql import SparkSession
warehouse_path = "s3://my-iceberg"
def create_spark_iceberg(catalog_nm: str) -> SparkSession:
url = "http://localhost:19120/api/v1"
ref = "main"
spark = (
SparkSession.builder.config(
"spark.jars.packages",
",".join(
[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.1",
"org.projectnessie.nessie-integrations:nessie-spark-extensions-3.5_2.12:0.79.0",
"software.amazon.awssdk:bundle:2.20.160",
]
),
)
.config(
"spark.sql.extensions",
",".join(
[
"org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions",
"org.projectnessie.spark.extensions.NessieSparkSessionExtensions",
]
),
)
.config("spark.sql.execution.pyarrow.enabled", "true")
.config(
f"spark.sql.catalog.{catalog_nm}.io-impl",
"org.apache.iceberg.aws.s3.S3FileIO",
)
.config(
f"spark.sql.catalog.{catalog_nm}",
"org.apache.iceberg.spark.SparkCatalog"
)
.config(
f"spark.sql.catalog.{catalog_nm}.catalog-impl",
"org.apache.iceberg.nessie.NessieCatalog",
)
.config(f"spark.sql.catalog.{catalog_nm}.warehouse", warehouse_path)
.config(f"spark.sql.catalog.{catalog_nm}.uri", url)
.config(f"spark.sql.catalog.{catalog_nm}.ref", ref)
.getOrCreate()
)
return spark
_catalog_nm = "iceberg_catalog"
spark = create_spark_iceberg(_catalog_nm)
table = f"{_catalog_nm}.{os.environ['DATABASE_NAME']}.{os.environ['TABLE_NAME']}"
spark.sql(f"create namespace {_catalog_nm}.{os.environ['DATABASE_NAME']}")
df = spark.createDataFrame(
[
("2021-01-01", 1, "A", "X", "2021-01-01"),
("2021-01-01", 2, "B", "Y", "2021-01-01"),
("2021-01-01", 3, "C", "Z", "2021-01-01"),
],
["col_1", "col_2", "col_3", "col_4", "col_5"],
)
df.writeTo(table).using("iceberg").partitionedBy(df.col_5).createOrReplace()
See the data in s3!
# you can locate your files of data layer
# in this folder hierarchy
aws s3 ls s3://my-iceberg
Fetch the metadata info from Nessie UI.
Nessie uses Git like semantics, so we can fetch metadata for any of the commits. This is very promising & exciting!
Reading data into Snowflake is the same as we did for the AWS Glue Data Catalog.
Voila! We have understood three vastly different ways of using Apache Iceberg with Read-Write-Vendor tradeoffs.
If your data architecture is currently based entirely on Snowflake, then you would need a hybrid architecture. A good architecture would:
🔼 Maximise the best of both Snowflake & Apache Spark compute
🔽 Minimise infra costs significantly
To begin with, converting the Snowflake table to Iceberg massively reduces the read costs. Engineers experienced in infra can also beat Snowflake’s storage pricing model with appropriate choice & configuration in storage to extract that savings juice.
As far as compute is concerned, I have put Spark primarily for PoC purposes.
Data engineers have been using multiple compute technologies & tools for a long time. Now they can bring their own tools to the party courtesy of Iceberg’s extensive integrations ecosystem.
Next steps
Readers will understand that the presentations of this blog are just the tip of the iceberg (no pun intended). Hardening such a system for production use cases requires analysis along multiple lines.
Hybrid Architecture Design.
a) Choice of compute layer
b) Choice of storage layer
c) ID’ing a control planeUpdates to the relevant ETL algorithms.
Migration strategy.
Upskilling ourselves to understand the corresponding DevOps.
I’ll be working on the next set of items here and publish follow-up articles that talk about the above items in the coming months. Meanwhile, HMU if you wish to go deeper into anything that I have written above.
Readers, I have compiled this article after reading multiple tutorials, how to guides, blog posts, videos & Stack Overflow posts, etc., and have then created the MVP for this post. Below are a few links for reference.
References
Snowflake Iceberg setup:
a) Document: https://docs.snowflake.com/en/user-guide/tables-iceberg
b) Tutorial: https://quickstarts.snowflake.com/guide/getting_started_iceberg_tables/index.html#0
c) Summary article: https://www.snowflake.com/blog/unifying-iceberg-tables/Apache Iceberg resources:
a) book: https://hello.dremio.com/wp-apache-iceberg-the-definitive-guide-reg.html
b) catalog summary by the same author: https://www.linkedin.com/pulse/deep-dive-concept-world-apache-iceberg-catalogs-alex-merced-u0ucc/AWS Glue as catalog:
a) tutorial 1: https://medium.com/@cesar.cordoba/how-to-work-with-iceberg-format-in-aws-glue-258bbcec52d7
b) tutorial 2: https://medium.com/softwaresanders/aws-glue-apache-iceberg-d3790c0e91a4Project Nessie as catalog:
a) official tutorial: https://github.com/projectnessie/nessie-demos/blob/main/notebooks/nessie-iceberg-demo-nba.ipynb
Working at Toplyne
We’re always looking for talented engineers to join our team. You can find and apply for relevant roles here.